

PDF is a format that cannot be captured and processed automatically without further ado. But don’t worry: We’ll show you how to do it anyway!
PDF documents are everywhere. So it’s no wonder if you ask yourself: How can I automatically capture PDF documents and import them into my system? Such automation would save time, money and effort – and increase the speed and accuracy of your processes! We’ll show you what stands in the way of automation and how to remove these obstacles.
What exactly is PDF anyway? And why do we use PDF in business?
PDF is short for “Portable Document Format” and is a file format that can be used to present and exchange documents digitally. The special feature here is that the creator defines the format so that it is always displayed in the same way, regardless of software, hardware and operating system. This means that documents can be displayed to every recipient in the way the creator intended. Where previously a paper document was created, printed and sent, PDF is the digital alternative!
It’s no wonder, then, that such a practical format has become an industry standard in business and is used more frequently to exchange information than almost any other file format. No matter where you look in a company, you’ll find PDF documents: invoices, orders, contracts, order confirmations, forms, delivery bills, presentations, price lists and much much more.
If this is also the case in your organization and you want to know how to capture PDF documents in an automatic, reliable and error-free way, you’ve come to the right place!
Automation desired?
With such a mass of PDF documents in a company’s daily routine, it makes sense to automate the capture and import of PDF data. Why go to the trouble of manually transferring item after item into the ERP system for each order? Why check each invoice manually to ensure that all amounts are correct? Why search every order confirmation for changes to the order? Especially when you are almost flooded with documents every day.
The advantages are numerous: Not only does automation save time, costs and effort in contrast to the manual capture of PDF documents. The error rate in data entry can also be reduced, as there are no number twists in order numbers or too many zeros in the price. If you look at the follow-up processes, it becomes obvious how positively this can affect the number of returns, complaints or payment errors. Your stakeholders will thank you!
The saved data entry effort naturally also leads to nice effects in the business processes: The fact that PDFs are read out in a matter of seconds means that order processing can start immediately. In purchasing, deviations in the order confirmation can be responded to immediately and production planning can be adjusted. In goods receiving, quality management can be completed more quickly. Employees who used to be up to their necks in documents can finally devote more time to their other tasks.
Unfortunately, however desirable and advantageous it may be to automatically extract and process information from PDF documents, it’s not that easy!

The problem with automatically processing PDF documents
PDF documents have one major disadvantage: They are not well suited for the automatic exchange of information! In most cases, the information from the PDF orders, invoices and forms is needed in an ERP system, accounting software or HR platform so that the data can be further processed there.
And this is precisely the catch: the data stored in PDF documents is unstructured. This means that there are no specifications as to which text contains the order number, where the delivery address is located or how the sender is identified. Ultimately, a PDF file only records where which text or which image is located – but not what this text means.
You have to gather and decipher this information yourself. A human being can do that, but it’s difficult for a machine. How is it supposed to recognize on its own which of the addresses is from the supplier and which is from the customer? Or what the article number is? There is software that tries to use artificial intelligence for this recognition. The problem is that complex information in particular cannot yet be reliably recognized in this way – humans have to help and check the processing.
But this is not the only problem. There are plenty of special cases that make it difficult for machines to automatically process PDF documents:
- Business partners send bizarre PDF layouts
- Important data is missing completely
- Article numbers have to be assembled from three separate components by yourself
- Customer article numbers have to be converted to supplier article numbers
- The delivery date is in the wrong date format, so that month and day are interchanged
- Etc.
Not easy to process, but still not impossible – thanks to semantic readout and PDF mapping!
Semantic readout – What is it?
So how does automation still work? How can I capture data from PDF documents automatically, reliably and without errors?
There are many tools and applications that can create a Word or XML document from a PDF document. These tools extract formatting instructions, fonts and layout information from the PDF. Thus, they can display which text is written in which font at a certain position on a page of the document (e.g. the text 2004789 is written in the font Arial 12pt at the position 120.32,360.98 on the document). Unfortunately, this is not enough to automatically extract all important information from PDF business documents such as orders or invoices and transfer it to the ERP system. For this purpose, we are missing the information that 2004789 is the order number.
To be able to automatically capture and process PDF documents, the information from the PDF must be converted into structured data. In this case, structured means that each piece of information is assigned a meaning. This principle is also used to exchange data in EDI.
This is where semantic readout comes into play. Semantics means “the meaning or content of a word, sentence or text” (see German dictionary Duden). We want to read texts from a PDF and fill them with meaning. The reader of the PDF document recognizes this sense from the context with other information on the PDF document. For example, the text 2004789 is preceded or preceded by “order number” or “number”. It is therefore immediately clear to the reader that this is the order number.
Just like a human reader, semantic reading can be used to assign the meaning “order number” to the text 2004789. This semantic recognition of PDF content is of course not limited to such simple elements as the order number, but extends to all data in a PDF business document. The result is a sequence of data such as order number, order date, delivery date, as well as information about each order item (supplier, buyer, GLN), item description, order quantity and unit, unit price, total price and so on. All captured data is provided with a unique meaning.

Reading PDFs semantically with PDF mapping
Okay, now we know what each piece of information on a PDF means. But is that enough to be able to read PDF documents automatically? The answer, as you can already guess, is no. Besides the meaning, we still need to determine where to find the data on the document, who sent the document in the first place, whether all the data we need is there, and whether we need to transform the data for our needs.
So semantic readout alone is not enough – we need PDF mapping as a framework to fully automatically process PDF documents.
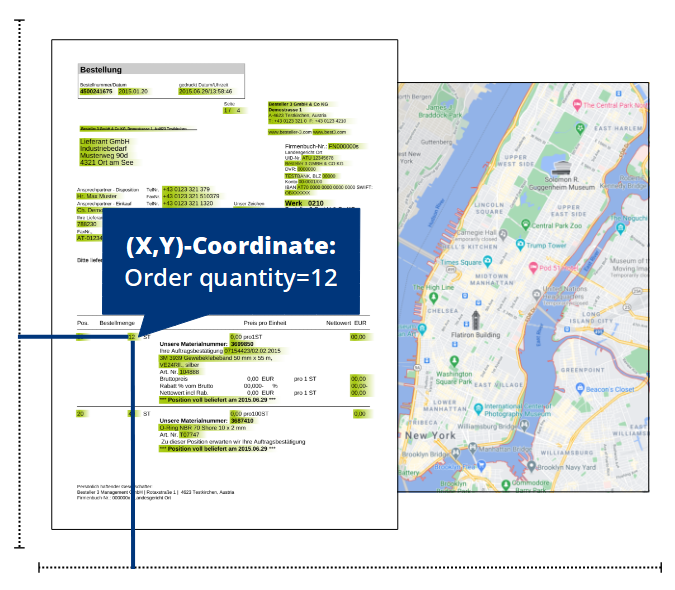
PDF mapping does not come from “map” for nothing. Just like creating a map with cities and streets, PDF mapping creates a kind of “map” with data from the PDF. While Google Maps captures the layout of our world, PDF Mapping documents the layout of a PDF file.
This makes sense because in business, every company usually uses a fixed layout for a PDF document type. So every PDF order from customer “A” looks basically the same and differs only in content. For example, the items are arranged in a table where the item number is on the left and next to it is the item description, quantity, order unit and price information. The items and their information change from order to order – but they are always arranged in the same order.
So if we know the PDF layout, we can use PDF Mapping to automatically process all PDF documents with this layout. Once again, the comparison with Google Maps comes in handy. Let’s take route planning: The actual layout of the world doesn’t change much either, but the content does. For example, the application dynamically shows us how much traffic is flowing on which roads.
Just as man has mapped the whole world, you can use PDF Mapping to map all the layouts of your incoming PDF documents. This is especially worthwhile for the layouts of which you receive PDF documents over and over again.
A software with PDF mapping and semantic readout
So far, so good! To sum it up in a few words: While semantic readout provides the PDF data with a meaning, PDF mapping reliably finds this data based on the PDF layout on each matching PDF document. The result of both techniques is structured PDF data – almost exactly as we need it for our ERP systems, accounting software or HR platforms!
But why only “almost”? Do you remember the special cases from earlier? What if data is missing or has to be changed? Keyword: Wrong date format or conversion of article numbers. And how do I get the structured data into my ERP system after all?
With our appropriately named PDF-Mapper software application, the complete process around semantic reading and PDF mapping can be realized. This process is supplemented by further automated process steps such as PDF input, data preparation, data validation and export. This means that even all special cases of PDF processing can be reliably solved. You can sit back and relax!
By semantically reading and PDF mapping a PDF layout once, PDF-Mapper can be used to fully automate PDF document processing. Once set up, the PDF Mapper works like an automatic converter. PDF data is captured in a structured manner as if it had already been transmitted in one of the numerous EDI (Electronic Data Interchange) or XML formats. These data formats were developed specifically for the error-free and direct exchange of information between machines.
As a result, PDF business documents such as orders, invoices, delivery bills, order confirmations, payment advices or price agreements are automatically captured, processed, and imported into the desired business software.

How exactly does the PDF-Mapper work?
That sounds exciting? Would you like to learn how PDF mapping and semantic readout are implemented in PDF-Mapper? And how exactly the numerous special cases in PDF-Mapper can be solved in a reliable, powerful process?
Read more in the second part of our series on PDF mapping or see for yourself and download the PDF-Mapper!
