

PDF-Dokumente können mit dem PDF-Mapper automatisch ausgelesen und in strukturierte EDI- oder XML-Dateien konvertiert werden. Erfahren Sie hier die 8 einfachen Schritte, die dazu notwendig sind.
Um die Unternehmensprozesse rund um eingehende PDF-Dokumente zu optimieren, benötigt man am besten einen Konverter von PDF zu EDI-/XML. Diese EDI-/XML-Dateien können in Warenwirtschaftssysteme eingelesen werden. Das Ergebnis ist ein automatisierter Prozess, in dem PDFs ausgelesen, verarbeitet, in EDI oder XML konvertiert und ins Warenwirtschaftssystem eingelesen werden, ohne dass ein Mensch eingreifen muss. Allerdings ist die Konvertierung etwas komplizierter als von Word zu PDF, PNG zu JPG oder WAV zu MP3. Wir zeigen Ihnen deshalb in 8 Schritten, wie die Konvertierung im PDF-Mapper eingerichtet wird, um PDF-Dokumente automatisch auslesen zu können.
Hintergrund: Wie man PDF-Dokumente strukturiert auslesen kann
PDF-Dokumente sind besonders im Geschäftsleben ein gängiges Dateiformat, um Informationen auszutauschen. Aber leider eignet sich PDF nicht gut dazu, um diese Informationen automatisch austauschen zu können. Denn: Maschinen können nicht so einfach wie wir erkennen, was die verschiedenen Informationen bedeuten und wo diese Informationen auf verschiedenen Dokumenten stehen.
Eine kleine Einführung zum PDF-Format, semantischem Auslesen und PDF-Mapping geben wir im ersten Artikel dieser Serie: PDF-Mapping – Wie man PDFs automatisch auslesen kann. Lesen Sie diesen Artikel zuerst, wenn Sie erfahren möchten:
- Was die Vorteile vom automatischen PDF-Auslesen sind,
- Warum PDFs schwer automatisch auszulesen sind,
- Welche Antwort semantisches Auslesen und PDF-Mapping bieten.
PDF zu EDI/XML konvertieren
Wir wollen uns an dieser Stelle aber der konkreten Anwendung von semantischem Auslesen und PDF-Mapping in der Software PDF-Mapper widmen.
Der PDF-Mapper nutzt semantisches Auslesen (Texte mit Bedeutung versehen) und PDF-Mapping (PDF-Layouts erfassen), um eingehende PDF-Geschäftsdokumente wie Aufträge, Rechnungen, Lieferscheine oder Auftragsbestätigungen automatisch und zuverlässig auslesen zu können. Er konvertiert diese PDF-Dokumente in EDI- oder XML-Dateien, die strukturiert in ERP- und Warenwirtschaftssysteme eingelesen werden können.
Wir erklären in diesem Teil unserer Serie PDF-Mapping, wie der PDF-Mapper einmalig eingerichtet wird, um PDF-Daten danach vollautomatisch auslesen, verarbeiten und konvertieren zu können. Hier sind Sie also richtig, wenn Sie erfahren möchten:
- Wie der PDF-Mapper PDFs zu strukturierten EDI-/XML-Daten für Ihr Warenwirtschaftssystem konvertieren kann,
- Warum der PDF-Mapper so zuverlässig mit 100% Genauigkeit funktioniert,
- Wie Sie selbst im PDF-Mapper die PDF-Mappings vornehmen können.

Probieren geht zusammen mit Studieren
Laden Sie sich direkt den PDF-Mapper herunter und probieren Sie kostenlos aus, wie der Prozess mit Ihren eigenen PDF-Dokumenten funktioniert. Folgen Sie diesem Link zum PDF-Mapper-Download und lesen Sie hier weiter, sobald Sie startklar sind!
Eine zeitliche Anmerkung: Normalerweise dauern die Schritte 1-6 nach ein bisschen Übung ca. 5-10 Minuten. Da dieser Artikel für Einsteiger geschrieben ist, erklären wir jeden Prozessschritt sehr ausführlich. Zudem betrachten wir auch einige Sonderfälle, damit Sie das volle Potential des PDF-Mappers nutzen können.
In 8 einfachen Schritten zum automatischen Auslesen von PDF-Dokumenten:
- Partner erfassen
- Was machen wir hier?
- Schritt für Schritt im PDF-Mapper
- Sonderfall 1.1: Verschiedene PDF-Dokumenttypen eines Partners auslesen
- Sonderfall 1.2: Ein Partner schickt einen PDF-Dokumenttyp in mehreren Layouts
- Sonderfall 1.3: Mehrere Partner schicken PDF-Dokumente mit demselben Layout
- Dokumenttyp wählen
- Was machen wir hier?
- Schritt für Schritt im PDF-Mapper
- Sonderfall 2.1: Ein hochgeladenes PDF-Dokument erkennt keine Texte/Textboxen
- Partner identifizieren
- Was machen wir hier?
- Schritt für Schritt im PDF-Mapper
- Sonderfall 3.1: Die Partneridentifikation durch Positionsangaben präzisieren
- Bereiche zuordnen
- Was machen wir hier?
- Schritt für Schritt im PDF-Mapper:
- Sonderfall 4.1: Ein PDF-Dokument hat keinen Fußbereich nach dem Positionsbereich
- Sonderfall 4.2: Ein PDF-Dokument wurde mit OCR-Texterkennung digital auslesbar gemacht
- Sonderfall 4.3: Ein PDF-Dokument hat mittig zentrierte statt links- oder rechtsbündig angeordnete Textboxen
- Sonderfall 4.4: Der Fangbereich soll nur für eine Angabe verändert werden
- Felder zuordnen
- Was machen wir hier?
- Schritt für Schritt im PDF-Mapper
- Exkurs: Zuordnungsregeln und reguläre Ausdrücke für Sonderfälle
- Sonderfall 5.1: Daten müssen anhand ihres Musters eindeutig erkannt werden
- Sonderfall 5.2: Textboxen müssen zusammengefügt werden
- Sonderfall 5.3: Verwechslungsgefahr bei Artikelnummern
- Sonderfall 5.4: Eine Adresse hat von PDF zu PDF verschieden viele Zeilen
- Mapping testen und anpassen
- Was machen wir hier?
- Schritt für Schritt im PDF-Mapper
- Exkurs: Funktionsbausteine
- Beispiel 6.1: Ein Datum automatisch formatieren
- Beispiel 6.2: Unnötige Texte entfernen
- Beispiel 6.3: Adressen automatisch aufteilen
- ERP-Integration einstellen
- Was machen wir hier?
- Schritt für Schritt im PDF-Mapper
- Sonderfall 7.1: Ich habe mehrere Schnittstellen für meine verschiedenen PDF-Dokumente
- Validierung einstellen
- Was machen wir hier?
- Schritt für Schritt im PDF-Mapper
- Sonderfall 8.1: Per E-Mail über fehlerhafte Belege benachrichtigt werden
- Ergebnis: Eingehende PDF-Dokumente automatisch im Hintergrund auslesen
- Was ist unser Ergebnis?
- Was passiert im PDF-Mapper?
- Wie kann ich starten?
Bevor wir damit anfangen, ein PDF-Dokument semantisch auszulesen (Schritt 5), nehmen wir im PDF-Mapping-Prozess zuerst ein paar grundlegende Einstellungen vor. Abgeschlossen wird das PDF-Mapping durch das Einstellen der ERP-Integration und der Validierung. Die Schritte 1-6 werden einmalig pro PDF-Layout vorgenommen, die Schritte 7-8 einmalig pro Schnittstelle Ihres ERP- oder Warenwirtschaftssystems. Danach verarbeitet der PDF-Mapper vollautomatisch im Hintergrund alle eingehenden PDF-Dokumente der eingerichteten PDF-Layouts.
1. Partner erfassen
Was machen wir hier?
Jeder Kunde oder Lieferant hat normalerweise ein festes, gleichbleibendes Layout für seine jeweiligen PDF-Dokumente. Die Dokumente werden heutzutage in den verschiedenen Softwareanwendungen automatisch generiert und mit den relevanten Bestell-, Rechnungs- oder anderen Daten befüllt. Leider verwendet jedes Unternehmen in der Regel sein eigenes Layout, sodass man von jedem Kunden und Lieferanten unterschiedlich aufgebaute PDF-Dokumente erhält.
Um PDF-Dokumente zuverlässig automatisch auslesen zu können, muss für jedes PDF-Layout ein PDF-Mapping eingerichtet werden – quasi eine „Landkarte“ des PDF-Layouts, in der die Koordinaten der verschiedenen Daten gespeichert werden. Damit lassen sich dann z. B. alle PDF-Bestellungen eines Kunden A oder alle PDF-Rechnungen eines Lieferanten B automatisch auslesen.
Damit der PDF-Mapper alle PDF-Belege dieses Kunden A auch dem Kunden A in Ihrem Warenwirtschaftssystem zuordnen kann, wird im PDF-Mapper im ersten Schritt immer der Partner erfasst. Der Firmenname und die passende ERP-ID des Partners (z. B. Kunden-, Debitor- oder Kreditornummer) reichen schon aus, allerdings kann man auch weitere Daten wie Adresse, Kontaktdaten, GLN und Steuernummer hinterlegen. Diese Daten können im PDF-Mapping-Prozess später automatisch den PDF-Daten hinzugefügt werden, falls z. B. die Adresse des Kunden nicht auf dem PDF-Dokument steht, aber in Ihrem ERP-System zusammen mit den Bestelldaten importiert werden muss.
Schritt für Schritt im PDF-Mapper
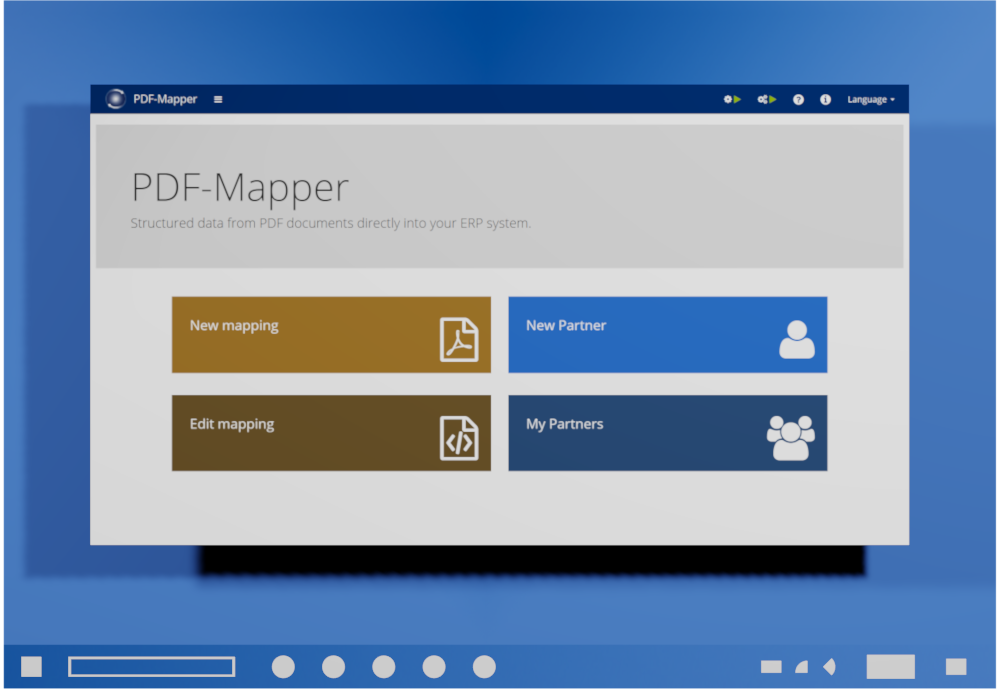
- Klicken Sie im Hauptmenü auf „Neuer Partner“, um einen neuen Partner zu erstellen.
- Geben Sie die ERP-ID (z. B. Kunden-, Debitor- oder Kreditornummer) und den Firmennamen des Partners ein.
- Wenn gewünscht, geben Sie weitere Daten wie GLN, Adresse, Kontaktdaten und Steuernummer ein.
- Klicken Sie auf „Speichern“.
Anmerkung: Sie können im Hauptmenü über „Meine Partner“ die eingegebenen Daten jederzeit verändern und den Partner löschen.
Sonderfall 1.1: Verschiedene PDF-Dokumenttypen eines Partners auslesen
Wenn Sie z. B. sowohl PDF-Bestellungen, als auch PDF-Rechnungen eines Partners automatisch auslesen möchten, können Sie nur einen Partner anlegen und die Schritte 2-6 einmal für PDF-Bestellungen und einmal für PDF-Rechnungen vornehmen.
Sonderfall 1.2: Ein Partner schickt einen PDF-Dokumenttyp in mehreren Layouts
Wenn ein Partner Ihnen z. B. PDF-Bestellungen in zwei verschiedenen Layouts sendet, dann können Sie zwei Partner mit derselben ERP-ID anlegen. Der PDF-Mapper erstellt jeweils eine eigene „BizzTainer-ID“, unter der das PDF-Mapping erstellt wird.
Sonderfall 1.3: Mehrere Partner schicken PDF-Dokumente mit demselben Layout
Manchmal kann es sein, dass mehrere Partner z. B. dasselbe Warenwirtschaftssystem verwenden, um Daten als PDF-Dokument zu exportieren. Dies ist vor allem bei Branchenlösungen der Fall. Hier muss für mehrere Partner nur ein Layout erfasst werden. Zwischen den Partnern wird dann über die PDF-Daten wie z. B. Adresse oder Kunden-/Lieferantennummer unterschieden. Spezielle ERP-IDs müssen Sie ggf. im Mapping ergänzen, wenn die Angaben nicht im PDF enthalten sind.
2. Dokumenttyp wählen
Was machen wir hier?
Wenn ein Mitarbeiter per Hand die Daten von einem Dokument erfassen soll, ermittelt dieser normalerweise zuerst den Dokumenttyp. Handelt es sich um eine Bestellung, eine Rechnung oder um ein anderes Dokument? Je nachdem, welcher Dokumenttyp vorliegt, gibt er die Daten an der passenden Stelle im Warenwirtschaftssystem ein.
Diese Unterscheidung des Dokumenttyps muss auch in einer Automatisierung erfolgen. Um die Daten einer Bestellung auch als Bestelldaten zu strukturieren und richtig ins Warenwirtschaftssystem einzulesen, müssen wir auswählen, für welchen PDF-Dokumenttypen wir das PDF-Mapping erstellen möchten.
In diesem Schritt laden wir auch ein beispielhaftes PDF hoch, anhand dessen wir das PDF-Mapping vornehmen werden.
Schritt für Schritt im PDF-Mapper
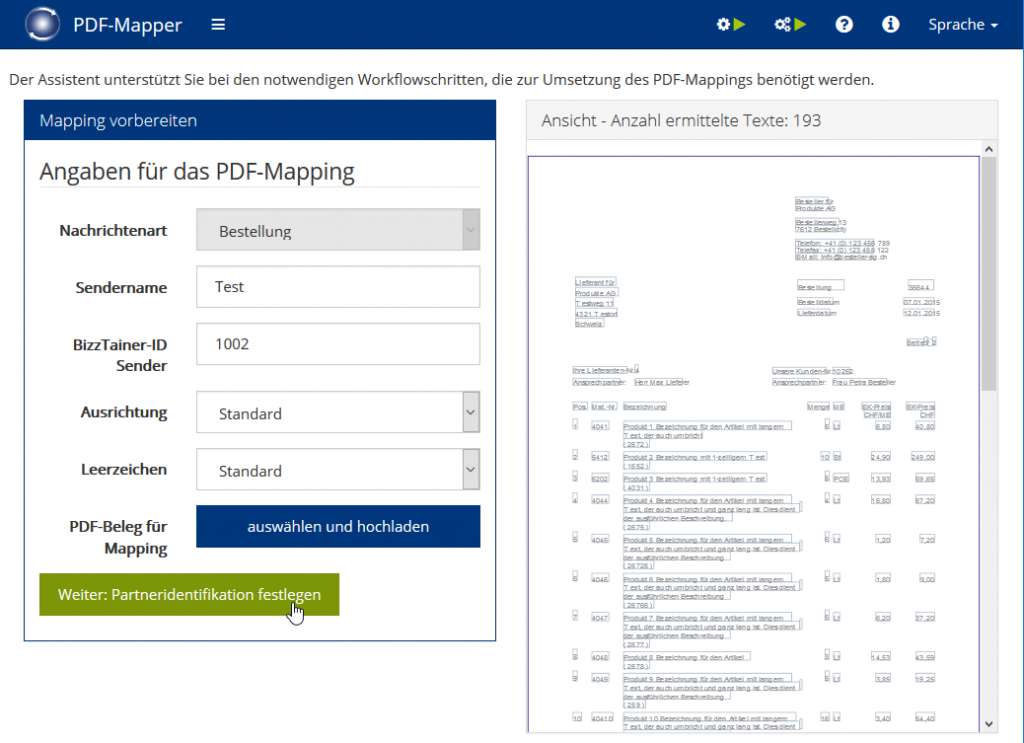
Nachrichtenart auswählen:
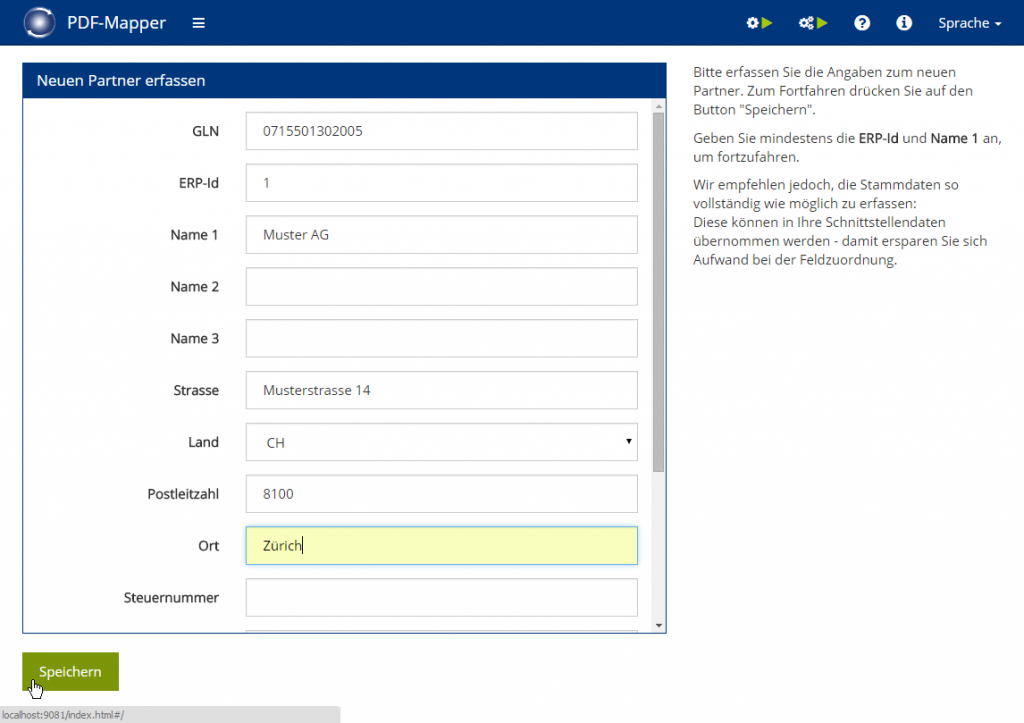
- Klicken Sie im Hauptmenü auf „Neues Mapping“, um ein neues PDF-Mapping zu erstellen.
- Wählen Sie aus der Liste den gewünschten Partner aus.
- Wählen Sie unter „Nachrichtenart auswählen“ aus, ob Sie das PDF-Mapping für Bestellungen oder Rechnungen erstellen möchten (für andere Dokumente siehe unten).
- Klicken Sie auf „Weiter: PDF hochladen“.
Andere Dokumente: Wenn Sie Preisabschlüsse, Lieferscheine oder Auftragsbestätigungen auslesen möchten, dann wählen Sie hier auch einfach „Bestellungen“. Für Zahlungsavise wählen Sie „Rechnungen“.
PDF hochladen:
- Wählen Sie ein typisches PDF-Dokument aus und laden Sie es hoch.
- Wenn das hochgeladene PDF-Dokument digital auslesbar ist, erscheint es in der rechten Ansicht mit ermittelten Texten, um die jeweils rechteckige Textboxen gezeichnet sind (ansonsten siehe Sonderfall 2.1).
- Klicken Sie auf „Weiter: Partneridentifikation festlegen“ klicken.
Ausrichtung: Je nachdem, wie das PDF formatiert ist, können die Textboxen anhand der linken oberen oder linken unteren Ecken ausgerichtet sein. Wenn beim Kopieren von Texten in ein Texttool wie Microsoft Word wie im Bild der Text2 vor Text1 steht, ist die Ausrichtung links oben (Ausrichtung „Standard“ wählen). Wenn Text1 vor Text2 steht, ist das Dokument anhand der Ecke links unten ausgerichtet (Ausrichtung „Grundlinie“ wählen).
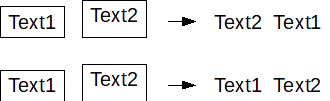
Leerzeichen: Je nachdem, wie das PDF formatiert ist, können Daten durch einige Leerzeichen getrennt sein. Diese oft störenden Leerzeichen können entweder automatisch entfernt werden (Leerzeichen-Einstellung „Standard“ wählen) oder behalten werden (Leerzeichen-Einstellung „belassen“ wählen). Letzteres kann sinnvoll sein, um Layouts auszulesen, die unterschiedliche Informationen in einer einzigen Textbox darstellen. Oft sehen solche Layouts aus, als wären Sie mit einer Schreibmaschine erstellt worden. Die Informationen können dann durch Ihre Position getrennt werden. Z. B. stehen Artiklenummern in der Textbox vom 5. bis zum 11. Zeichen und die Bestellmenge zwischen Zeichen 21 bis 26.
Sonderfall 2.1: Ein hochgeladenes PDF-Dokument erkennt keine Texte/Textboxen
Für PDF-Mapping müssen PDF-Dokumente digital auslesbar sein. Daher können PDFs mit eingescannten Seiten oft nicht verarbeitet werden. Lassen Sie sich von Ihrem Partner die Bestellung bzw. Rechnung direkt aus seinem System als PDF zusenden. Alternativ können Sie mit Hilfe einer externen OCR-Software aus dem Fax- oder Scan-Abbild ein digital auslesbares PDF erstellen.
Mit unserem PDF-Check können Sie testen, ob Ihre PDFs digital auslesbar sind.
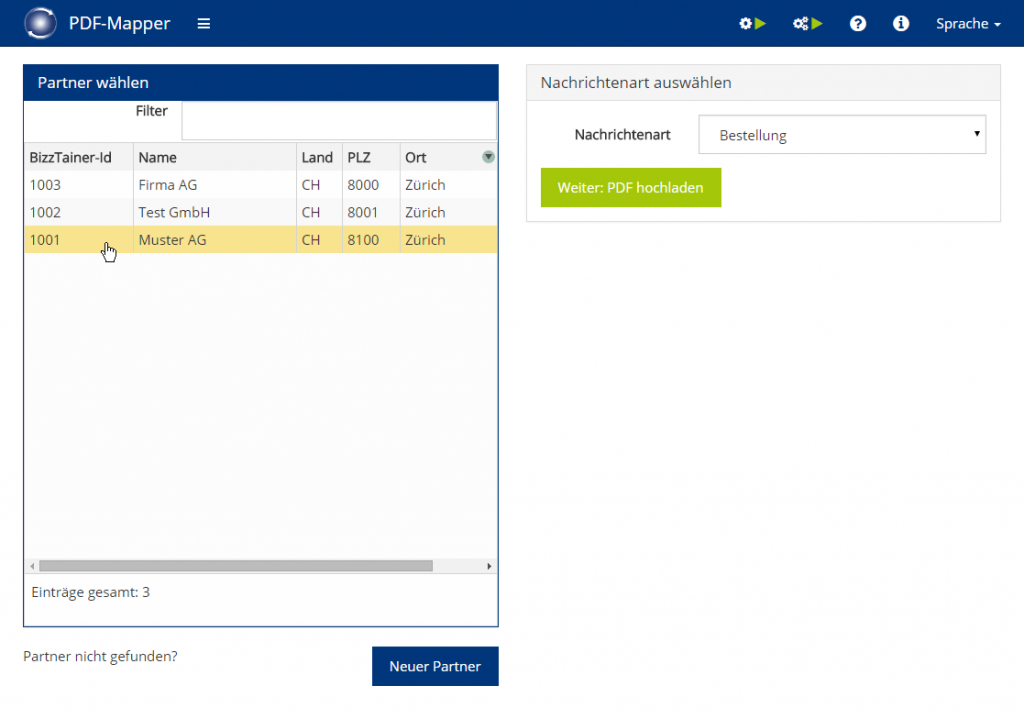
3. Partner identifizieren
Was machen wir hier?
Im Erfassungsprozess eines Dokuments ist der Absender die zweite grundlegende Information neben dem Dokumenttyp. Wir haben schon den Partner im PDF-Mapper angelegt, aber wir müssen sicherstellen, dass er auch immer als Absender seiner PDF-Dokumente erkannt wird.
Damit ein Partner automatisch identifiziert wird, können Angaben wie die Steuer-ID, Firmenname oder E-Mail-Domain des Senders als Kriterien zur automatischen Erkennung festgelegt werden. Diese Kriterien müssen auf jedem PDF-Dokument des Partners vorhanden sein und sollten so eindeutig sein, dass sie nicht auf PDF-Dokumente anderer Partner zutreffen können. Wir empfehlen deshalb bei nicht eindeutigen Angaben, eine Kombination mehrerer Kriterien auszuwählen.
Schritt für Schritt im PDF-Mapper
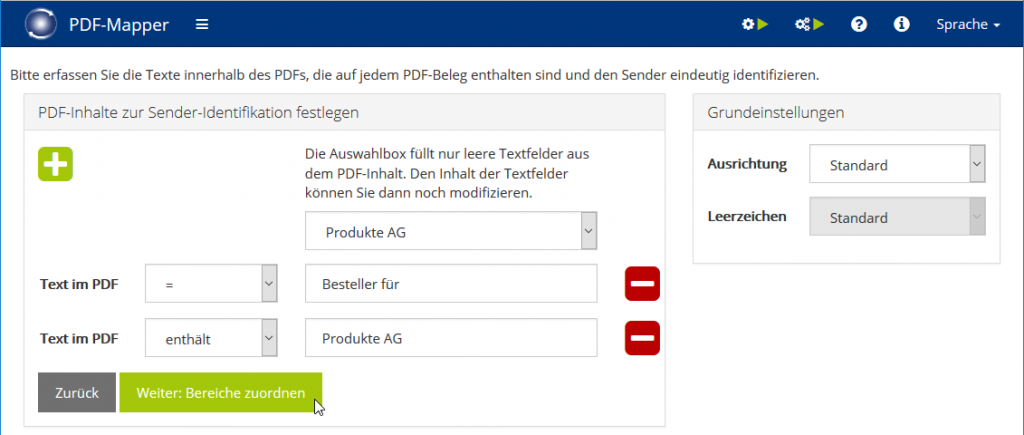
- Wählen Sie eine Angabe zur eindeutigen Partneridentifikation aus dem Drop-Down-Menü (z. B. Firmenname, Steuernummer, E-Mail-Adresse) – die Angabe wird in das Kriterien-Feld darunter übernommen.
- Passen Sie die Angabe im Kriterien-Feld ggf. an (z. B. E-Mail-Adresse zu E-Mail-Domain kürzen).
- Wählen Sie aus, wann das Kriterium erfüllt ist (siehe “Kriterien setzen”)
- Fügen Sie ggf. über das „+“ weitere Kriterien hinzu und wiederholen Sie die Schritte 1-3.
- Fahren Sie mit „Weiter: Bereiche zuordnen“ fort.
Kriterien setzen: „=“: Text im PDF entspricht genau der Angabe „enthält“: Text im PDF enhält die Angabe „beginnt mit“: Text im PDF beginnt mit der Angabe „entspricht regulärem Ausdruck“: Mit einem regulären Ausdruck kann man z. B. einstellen, dass im PDF entweder eine Angabe A oder B stehen kann. Beispiel: (DE0185|AT6789) bedeutet, dass der Partner identifiziert wird, wenn auf dem PDF entweder DE0185 oder AT6789 steht.
Anmerkung: In den Grundeinstellungen rechts können Sie noch die Ausrichtung ändern (analog zum Schritt beim PDF hochladen), nicht aber die Leerzeichen-Einstellung.
Sonderfall 3.1: Die Partneridentifikation durch Positionsangaben präzisieren
Wenn Sie „Text im PDF“ durch eine andere Option ersetzen, können Sie zusätzlich Bereiche auf dem PDF-Layout festlegen, in denen die gesetzten Kriterien zu finden sein müssen:
- Text an Position oben, links:
Die Angabe muss rund um die gewählte Position zu finden sein, damit das Kriterium erfüllt ist. Die Position wird mit Koordinaten in Dokumenteinheiten angegeben. Eine Abweichung von den Koordinaten kann mit dem Fangbereich +/- erhöht oder verringert werden. - Text an Position oben:
Die Angabe muss rund um die gewählte Zeile zu finden sein, damit das Kriterium erfüllt ist. Die Zeile wird mit der horizontalen Koordinate angegeben, die mögliche Abweichung mit dem Fangbereich. - Text an Position links:
Die Angabe muss rund um die gewählte Spalte zu finden sein, damit das Kriterium erfüllt ist. Die Spalte wird mit der vertikalen Koordinate angegeben, die mögliche Abweichung mit dem Fangbereich.
4. Bereiche zuordnen
Was machen wir hier?
Wie in unserem Artikel rund um PDF-Mapping erklärt, erstellen wir im Grunde genommen eine „Landkarte“ des PDF-Layouts. Ähnlich wie auf einer Landkarte Berge, Wälder und Gewässer erfasst werden, markieren wir zunächst auf dem PDF die verschiedenen Dokumentenbereiche.
Denn: Geschäftsdokumente wie Aufträge und Rechnungen lassen sich in der Regel in verschiedene Dokumentenbereiche wie den Kopf-, Positions- und Fußbereich unterteilen. In allen drei Dokumentenbereichen können sich wichtige Daten befinden, die ausgelesen werden müssen, damit der Empfänger des Geschäftsdokuments alle benötigten Angaben hat, um z. B. die bestellten Artikel zu liefern oder die Rechnung fristgerecht zu bezahlen.
Im Kopfbereich auf der ersten Seite stehen je nach Dokumenttyp wichtige Informationen wie Bestellnummer, Rechnungsdatum, Käuferadresse und Lieferantenangaben. Auf den Folgeseiten gibt es zudem oft einen verkürzten Kopfbereich, wo ein Teil dieser Informationen wiederholt wird.
Der Positionsbereich kann sich über mehrere Seiten ziehen und ist oft wie eine Tabelle in Zeilen und Spalten angeordnet. Er beinhaltet z. B. eine Auflistung von Artikeln, die bestellt oder in Rechnung gestellt werden. Meistens haben die Spalten jeweils eine Spaltenüberschrift, in der die Bedeutung der Daten angegeben ist – z. B. Artikelnummer, Menge oder Preis. Die Zeilen sind oft durchnummeriert.
Der Fußbereich befindet sich oft auf der letzten Seite unter dem Positionsbereich und beinhaltet zusammenfassende oder zusätzliche Informationen.
Damit PDFs mit dem PDF-Mapper automatisch ausgelesen und richtig aufbereitet werden können – selbst bei komplexen PDF-Layouts und abenteuerlichen Zusammenstellungen von Daten -, müssen die einzelnen Dokumentenbereiche einmalig markiert werden.
Schritt für Schritt im PDF-Mapper:
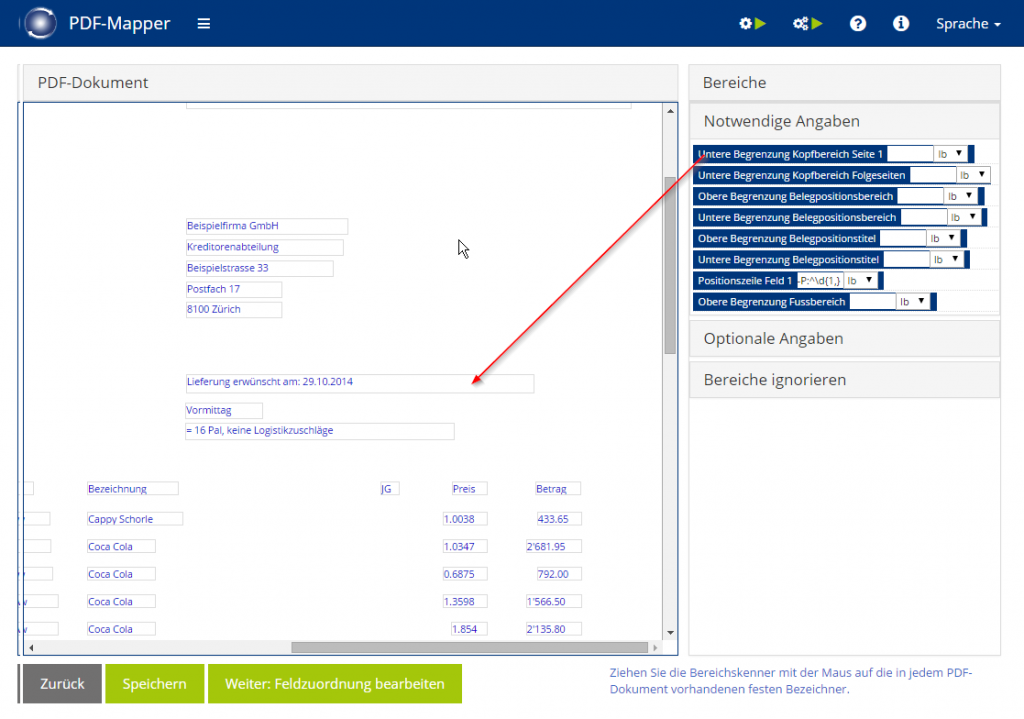
- Ziehen Sie nacheinander die „Notwendigen Angaben“ per Drag & Drop auf die entsprechenden Felder, die den Beginn oder das Ende des Dokumentbereichs markieren:
- Untere Begrenzung Kopfbereich Seite 1:
Markieren Sie das horizontal unterste Feld des Kopfbereichs auf Seite 1. - Untere Begrenzung Kopfbereich Folgeseiten:
Markieren Sie das horizontal unterste Feld des Kopfbereichs auf Seite 2 (wenn vorhanden, ansonsten dasselbe Feld wie in Schritt 1 markieren). - Obere Begrenzung Belegpositionsbereich:
Markieren Sie das horizontal oberste Feld des gesamten Positionsbereichs. - Obere/Untere Begrenzung Belegpositionstitel:
Markieren Sie im Positionsbereich das horizontal oberste und unterste Feld der Spaltenüberschriften. - Positionszeile Feld 1:
Markieren Sie im Positionsbereich das erste Feld in der ersten Zeile (oft die erste Positionsnummer). - Untere Begrenzung Belegpositionsbereich:
Markieren Sie das horizontal unterste Feld des gesamten Positionsbereichs. - Obere Begrenzung Fußbereich:
Markieren Sie das horizontal oberste Feld des Fußbereichs auf der letzten Seite.
- Überprüfen Sie, ob die markierten Felder links- oder rechtsbündig ausgerichtet sind (siehe unten).
- Fügen Sie ggf. optionale Angaben oder zu ignorierende Bereiche hinzu (siehe unten).
- Klicken Sie auf „Speichern“, um den aktuellen Stand zu speichern.
- Klicken Sie auf „Weiter: Feldzuordnung bearbeiten“, um fortzufahren.
Welche Felder markieren?: Alle Felder, die Sie markieren, müssen in allen PDF-Dokumenten mit diesem Layout vorkommen, damit die automatische Verarbeitung reibungslos laufen kann. Wenn Sie sich nicht sicher sind, vergleichen Sie ein paar PDF-Dokumente mit demselben Layout, um diese Felder herauszufinden. Stellen Sie auch sicher, dass Sie eindeutige Angaben verwenden. Beispielsweise wird oft „Pos“ zur Angabe der Positionszeile verwendet, kommt aber gerne auch im Dokumentfuß unter „Pos“tanschrift vor (→ -P: und regulärer Ausdruck).
Felder mehrfach markieren: Ein Feld kann mehrmals markiert werden. Wenn es auf einer horizontalen Linie mehrere Felder gibt, ist in der Regel egal, welches Feld Sie markieren.
Links- und rechtsbündig: Überprüfen Sie, ob die Textboxen (nicht die Texte selbst!) in ihrer Spalte links oder rechtsbündig angeordnet sind. Wählen Sie dann im blauen Element im Dropdown-Menü entweder „lb für linksbündig oder „rb“ für rechtsbündig. Sind Sie unsicher, so verwenden Sie zunächst „lb“ und überprüfen anschließend das Mappingergebnis. Wird der Inhalt nicht korrekt erkannt, wechseln Sie zu „rb“.
Optionale Angaben: Falls tabellarische Angaben in Kopf- oder Fußbereich (z. B. Angaben zu Rabatten oder Steuersätzen) oder sich wiederholende Bemerkungen (z. B. Referenzen wie Projektnummern und Kostenstellen) vorkommen, können Sie diese mit den „Optionalen Angaben“ markieren. Dadurch können auch diese Angaben zuverlässig und strukturiert ausgelesen werden.
Bereiche ignorieren: Falls bestimmte Bereiche ignoriert werden sollen, können Sie diesen mit den Feldern aus „Bereiche ignorieren“ markieren.
Sonderfall 4.1: Ein PDF-Dokument hat keinen Fußbereich nach dem Positionsbereich
In diesem Fall müssen nicht alle „Notwendigen Angaben“ zugeordnet werden: Die „Obere Begrenzung Fussbereich“ und „Untere Begrenzung des Positionsteils“ können weggelassen werden.
Sonderfall 4.2: Ein PDF-Dokument wurde mit OCR-Texterkennung digital auslesbar gemacht
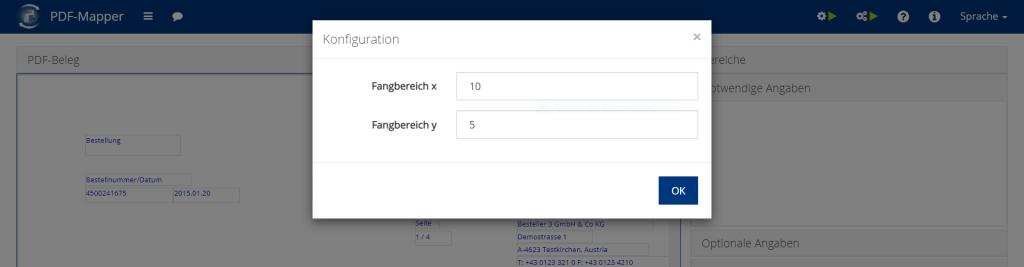
PDF-Dokumente, die mit OCR-Texterkennung digital auslesbar gemacht wurden, haben oft nicht „sauber“ angeordnete Textboxen. Die Positionen dieser Textboxen verschieben sich um einige Pixel in verschiedene Richtungen. Um solche PDFs trotzdem zuverlässig auslesen zu können, kann man den Fangbereich erweitern. Der Fangbereich gibt die Abweichung dieser Positionen auf dem PDF an, innerhalb welcher der PDF-Mapper die Angaben suchen soll.
Wenn wir also normalerweise eine Angabe an der Position (10, 20) auf dem PDF finden, können wir den Fangbereich auf x=5 und y=5 erhöhen, sodass der PDF-Mapper die Angabe zwischen den Positionen (5, 15) und (15, 25) sucht.
Um den Fangbereich einzustellen, klicken Sie auf das Einstellungs-Symbol im Bereich „PDF-Dokument“. Stellen Sie dann den gewünschten Fangbereich ein. Bei OCR-Texterkennung sollten Sie die Werte für x und y erhöhen. Ein PDF-Dokument im A4-Hochformat wird normalerweise mit x=595 Einheiten und y=842 Einheiten ausgelesen.
Sonderfall 4.3: Ein PDF-Dokument hat mittig zentrierte statt links- oder rechtsbündig angeordnete Textboxen
Bei mittig zentrierten Textboxen können Sie wie bei Sonderfall 4.2 den Fangbereich erhöhen. Klicken Sie auf das Einstellungs-Symbol im Bereich „PDF-Dokument“ und erhöhen Sie den Fangbereich x. Den Fangbereich y brauchen Sie nicht verändern.
Sonderfall 4.4: Der Fangbereich soll nur für eine Angabe verändert werden
Um den Fangbereich für eine bestimmte Angabe zu verändern, können Sie in das Eingabefeld im blauen Element eine Zuordnungsregel eintragen:
- -X:{n} mit einer positiven Zahl n für den x-Fangbereich (nach rechts und links von der Position aus).
- -DY:{n} mit einer positiven Zahl n für den y-Fangbereich (nach oben und unten von der Position aus).
- -Y:{n} mit einer positiven Zahl n für den y-Fangbereich nach unten
- -Y:{n} mit einer negativen Zahl n für den y-Fangbereich nach oben
5. Felder zuordnen
Was machen wir hier?
Die Feldzuordnung ist der zentrale Schritt im PDF-Mapper, um eine automatische PDF-Datenverarbeitung möglich zu machen.
Erinnern Sie sich an semantisches Auslesen? Falls nicht, gibt es im ersten Teil unserer Serie zum PDF-Mapping die Lang- und im Folgenden die Kurzfassung: Um die Daten aus PDF-Dokumenten automatisch auslesen und in ERP- oder Warenwirtschaftssysteme einlesen zu können, müssen wir diese zuerst in strukturierte Daten umwandeln. Um die PDF-Daten zu strukturieren, müssen wir sie jeweils mit einer Bedeutung versehen werden. Das heißt die Bestellnummer muss als Bestellnummer markiert werden, das Lieferdatum als Lieferdatum, die Artikelnummern als Artikelnummern. Das nennen wir semantisches Auslesen.
Zusätzlich müssen diese Daten auf jedem PDF eines Layouts wiedergefunden werden. Dazu markieren wir die Koordinaten, an denen die Daten stehen, auf unserer PDF-Mapping-„Landkarte“. Diese Koordinaten können absolut oder relativ zu einem Anker sein. Wenn z. B. die Bestellnummer immer an derselben Position zu finden ist, speichern wir diese absolute Position. Wenn die Bestellnummer von PDF zu PDF an unterschiedlichen Positionen, aber immer hinter einem Text „Bestell-Nr.“ zu finden ist, speichern wir die relative Position zu diesem Anker-Text.
Im PDF-Mapper werden das semantische Auslesen und PDF-Mapping der Daten in einem Schritt vereint. Einmalig zeigen Sie dem PDF-Mapper, wo die Daten stehen, die Sie automatisch auslesen möchten und versehen die Daten gleichzeitig mit ihrer Bedeutung. Der PDF-Mapper merkt sich die Angaben und findet die relevanten Daten auf jedem weiteren eingehenden PDF-Dokument mit diesem Layout!
Mit der Feldzuordnung erstellt der PDF-Mapper dann aus jedem PDF eine grundlegende XML-Datenstruktur, in der alle relevanten Daten zusammen mit ihrer Bedeutung automatisch eingetragen werden. Diese Struktur kann in den weiteren Schritten angepasst werden, um die Daten wie gewünscht aufzubereiten.
WICHTIG:
Nur die Felder der ersten Zeile im Positionsbereich sollten blau angezeigt werden, während die weiteren Zeilen ausgegraut sein sollten. Werden die Inhalte aller Zeilen blau angezeigt, dann korrigieren Sie die Bereichszuordnung. Nach der ersten Feldzuordnung können Sie die Bereichszuordnung nicht mehr ändern, ohne die komplette Feldzuordnung zu löschen.
Schritt für Schritt im PDF-Mapper
- Finden Sie die Datenfelder auf dem PDF, die sie gerne auslesen möchten.
- Suchen Sie in den Kategorien rechts die passenden Bedeutungen für die Datenfelder.
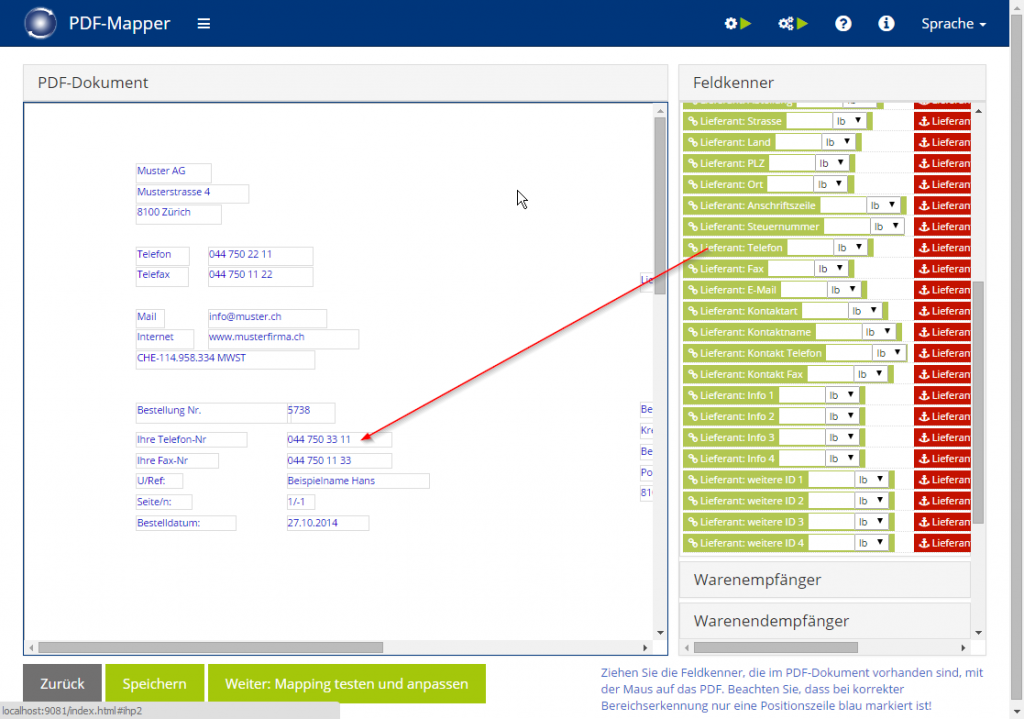
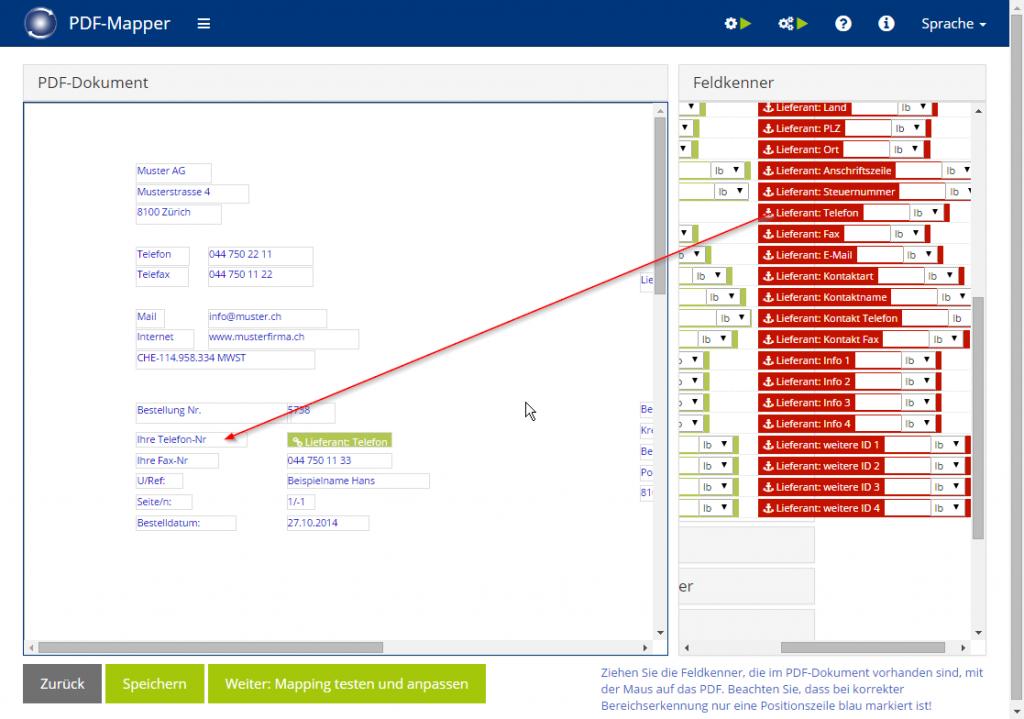
- Ziehen Sie per Drag & Drop die grünen Elemente auf die passenden Datenfelder.
- Falls sich ein Datenfeld von PDF zu PDF verschieben kann, ziehen Sie den passenden orangenen Anker auf einen Text, der auf das Datenfeld hinweist und/oder sich immer in relativer Nähe zum Datenfeld befindet.
- Überprüfen Sie, ob die markierten Felder links- oder rechtsbündig ausgerichtet sind (siehe unten).
- Klicken Sie auf „Speichern“, um den aktuellen Stand zu speichern.
- Wenn Sie alle relevanten Daten auf dem PDF-Dokument markiert haben, klicken Sie auf „Weiter: Mapping testen und anpassen“, um fortzufahren.
Felder mehrmals markieren: Es ist möglich, einem Feld auf dem PDF-Dokument mehrere Elemente zuzuordnen, z. B. mit einem grünen und einem orangenen Element.
Felder im Positionsbereich zuordnen: Im Positionsbereich sind Daten normalerweise in einer Tabelle mit Zeilen und Spalten angeordnet. Hier müssen Sie nur die relevanten Daten in der ersten Zeile zuordnen, um alle Zeilen automatisch auslesen zu können. Wenn Sie die relevanten Daten mit der passenden grünen Bedeutung markieren (z. B. die Artikelnummer 51203), werden diese immer anhand ihrer relativen Position zum Tabellenbeginn erkannt. Falls sich Texte in dieser relativen Position zum Tabellenbeginn verschieben können, markieren Sie zusätzlich einen passenden Text mit dem passenden orangenen Anker (z. B. Art.Nr. Vor 51203). Dadurch wird das markierte grüne Element relativ zum Anker gesucht.
Links- und rechtsbündig: Überprüfen Sie, ob die Textboxen (nicht die Texte selbst!) in ihrer Spalte links oder rechtsbündig angeordnet sind. Wählen Sie dann im blauen Element im Dropdown-Menü entweder „lb für linksbündig oder „rb“ für rechtsbündig. Sind Sie unsicher, so verwenden Sie zunächst „lb“ und überprüfen anschließend das Mappingergebnis. Wird der Inhalt nicht korrekt erkannt, wechseln Sie zu „rb“.
Exkurs: Zuordnungsregeln und reguläre Ausdrücke für Sonderfälle
In manchen Fällen können Daten durch eine einfache Verknüpfung nicht eindeutig zugeordnet werden, z. B. weil sich die Daten von Position zu Position oder von PDF zu PDF an unterschiedlichen Stellen befinden und mit anderen Daten verwechselt werden könnten.
Damit auch solche Daten immer eindeutig zugeordnet werden können und alle PDF-Dokumente fehlerfrei automatisch ausgelesen werden können, gibt es im PDF-Mapper eine Reihe an Zuordnungsregeln und reguläre Ausdrücke, die in das weiße Feld in den grünen und orangenen Elementen eingetragen werden können.

Mithilfe von Zuordnungsregeln lassen sich Texte aus mehreren Textboxen zusammenfügen und gegebenenfalls mit einem Zeichen trennen (siehe Sonderfall 5.2).
Mithilfe von regulären Ausdrücken können Daten anhand ihrer Eigenschaften und Muster erkannt werden. Damit wird es z. B. möglich, alle Wörter aus einer Wortliste herauszusuchen, die mit S beginnen und auf D enden, ohne die Anzahl der dazwischenliegenden Zeichen zu kennen. Oder Artikelnummern anhand ihrer Struktur von 6 Zahlen zu erkennen (siehe Sonderfall 5.1).
Zuordnungsregeln und reguläre Ausdrücke können kombiniert werden, um Daten eindeutig zu erkennen.
Sonderfall 5.1: Daten müssen anhand ihres Musters eindeutig erkannt werden
Verwenden Sie reguläre Ausdrücke (siehe Exkurs), um Daten über ihr Muster eindeutig erkennen zu können. Einem regulären Ausdruck muss im Eingabefeld immer -P: vorangestellt werden, z.B. -P:\d{1,}, dabei ist \d{1,} der eigentliche reguläre Ausdruck.
In der folgenden Tabelle finden Sie häufig vorkommende reguläre Ausdrücke zur Erkennung von bestimmten Mustern:
| Regulärer Ausdruck | Beschreibung |
| abc | Findet Zeichenketten, in denen ‘abc’ min. einmal vorkommt. |
| [abc] | Findet Zeichenketten, in denen entweder a, b oder c vorkommt. |
| [0-6] | Findet Zeichenketten, in denen eine Zahl zwischen 0 und 6 vorkommt. |
| ^a | Findet Zeichenketten, die mit einem ‘a’ beginnen. |
| $a | Findet Zeichenketten, die mit einem ‘a’ beendet werden. |
| ab[cd] | Findet Zeichenketten, die ein ‘ab’ sowie ein c oder d beinhalten (abc oder abd). |
| abc\B | Findet Zeichenketten, die ein ‘abc’ beinhalten, nicht aber damit enden. |
| ^\d{6}$ | Findet Zeichenketten, die exakt aus 6 Ziffern bestehen. |
| .ab | Findet Zeichenketten, die aus drei Zeichen bestehen und bei denen die letzten zwei Zeichen ‘ab’ sind. |
| .+ | Findet Zeichenketten, die aus mindestens einem Zeichen bestehen. |
| ^\d{1}.* | Findet Zeichenketten, die mit einer Ziffer beginnen und danach beliebig viele beliebige Zeichen enthält. |
Sonderfall 5.2: Textboxen müssen zusammengefügt werden
Verwenden Sie Zuordnungsregeln (siehe Exkurs), um Daten aus mehreren Textboxen zusammenfügen und ggf. mit einem Zeichen zu trennen. Die Zuordnungsregel kann im Eingabefeld des Ankers oder des grünen Elements eingetragen werden. Mehrere Zuordnungsregeln können hintereinander aufgeführt werden.
In der folgenden Tabelle finden Sie häufig genutzte Zuordnungsregeln:
| Zuordnungsregel | Beschreibung |
| -P:{regular expression pattern} | Leitet einen regulären Ausdruck ein. |
| -J:{m} | Fasst alle Textboxen zusammen, die m Einheiten rechts von der gewählten Textbox stehen. |
| -R:{m} | Fasst alle Textboxen zusammen, die m Einheiten links von der gewählten Textbox stehen. |
| -T:{m} | Fasst alle Textboxen zusammen, die m Einheiten über der gewählten Textbox stehen. |
| -B:{m} | Fasst alle Textboxen zusammen, die m Einheiten unter der gewählten Textbox stehen. |
| -C:{chars} | Trennt die zusammengefügten Textboxen mit einem Zeichen chars (| oder __ oder , oder %32 für Leerzeichen). |
Sonderfall 5.3: Verwechslungsgefahr bei Artikelnummern
Manchmal kann es sein, dass Artikelbeschreibungen in Positionen unterschiedlich lang sind und sich dementsprechend über verschieden viele Zeilen erstrecken. Wenn Artikelnummern unter der Artikelbeschreibung angegeben sind, haben diese keine feste relative Position zum Zeilenanfang mehr.
Oft kommt dann noch Verwechslungsgefahr hinzu, weil die Artikelbeschreibungen auch Größen oder andere Angaben beinhalten, die ähnlich wie die Artikelnummern aus Zahlen bestehen.
Da Artikelnummern aber meist einem bestimmten Muster folgen, kann man ein grünes Element wie gehabt auf die Artikelnummer setzen. Dann setzt man einen Anker auf dasselbe Feld und gibt in die Eingabemaske den passenden regulären Ausdruck ein (siehe Exkurs oben).
Wenn die Artikelnummer z. B. immer eine 6-stellige Zahlenfolge ist, würden Sie P:^\d{6}$ eintragen. Dabei ist -P: die Kennung für den nachfolgenden regulären Ausdruck ^\d{6}$, der besagt, dass der Text am Anfang (^) 6 numerische Zeichen hat (\d{6}) und dann endet ($).
Auf diese Art und Weise können Sie anhand von Mustern Artikelnummern oder auch andere Angaben zuverlässig auf jedem PDF-Beleg automatisch auslesen.
Sonderfall 5.4: Eine Adresse hat von PDF zu PDF verschieden viele Zeilen
Manchmal kann es sein, dass bei Adressen variabel viele Zeilen angegeben werden (z. B. manchmal eine Lieferadresse mit 4 Zeilen, manchmal mit 5 Zeilen).
Für solche variablen Adressangaben empfehlen wir eine Kombination von zwei Zuordnungsregeln. Ziehen Sie das passende grüne und orangene Element auf das oberste Adressfeld. In das orangene Anker-Element schreiben Sie -B:{m} mit m Einheiten, um alle Felder in m Einheiten unter dem obersten Adressfeld zusammenzufügen. Dahinter vermerken Sie z. B. -C:|, um die Felder mit | zu trennen.
Setzen Sie m groß genug, um Adressen mit der gewünschten Zeilenanzahl erfassen zu können. Anhand dieser Zuordnungsregeln können Sie die Adresse im Schritt „Mapping testen und anpassen“ variabel weiterverarbeiten.
6. Mapping testen und anpassen
Was machen wir hier?
Fast fertig! Im letzten Schritt des eigentlichen PDF-Mapping-Prozesses können wir die ausgelesenen PDF-Daten überprüfen und anpassen. Dadurch stellen wir sicher, dass die Daten richtig und wie gewünscht an das ERP-System übergeben werden können.
So können z. B. Datumsangaben in ein Standardformat transformiert (07.12.2014 → 2014-12-07), Dezimalzahlen aufbereitet (2’780,90 → 2780.90) oder begleitende Texte entfernt werden (Bestellnr. 345234 → 345234). Darüber hinaus lassen sich auch Identifikationsnummern aus Tabellen (z. B. fehlende GLNs oder Artikelnummern) automatisch hinzufügen und viele weitere Datenanpassungen automatisch vornehmen.
Nach diesen Aufbereitungen stehen die aus dem PDF extrahierten Daten im sogenannten Neutralformat zur Verfügung. Damit haben Sie das PDF-Mapping erfolgreich durchgeführt.
Falls Sie zum allerersten Mal ein PDF-Mapping durchführen, können Sie danach noch die Integration zum ERP-System vorbereiten und die automatische Validierung einstellen.
Falls Sie das schon getan haben, können Sie die automatische Verarbeitung für PDF-Dokumente dieses PDF-Layouts direkt starten!
Schritt für Schritt im PDF-Mapper
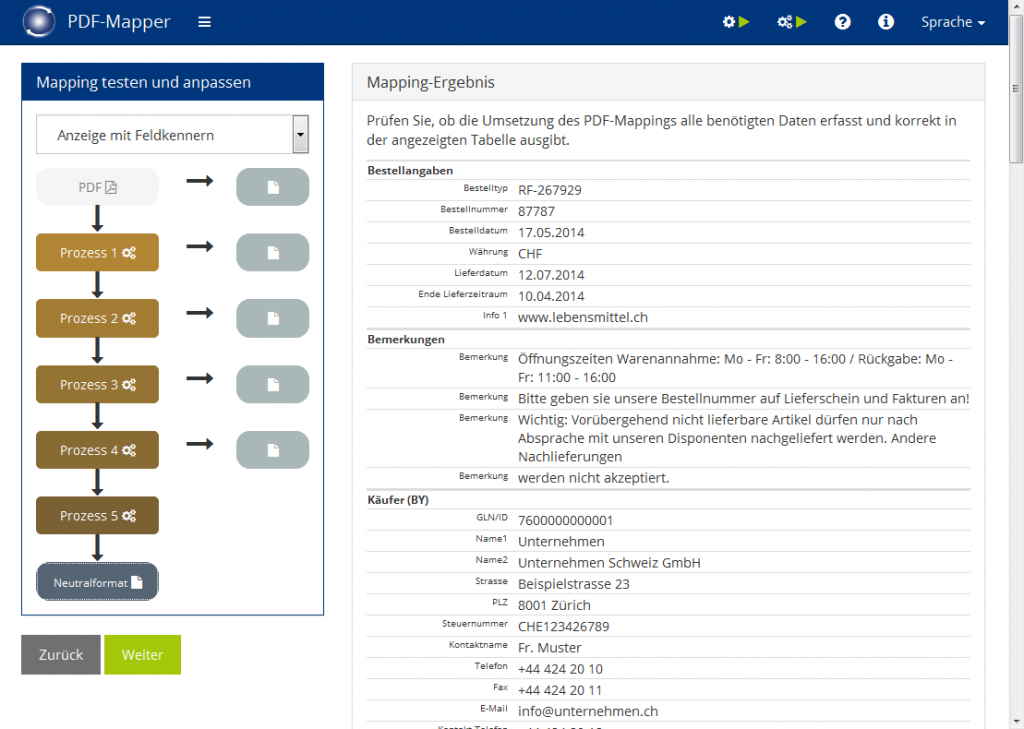
- Klicken Sie auf „Neutralformat“, um die ausgelesenen PDF-Daten angezeigt zu bekommen.
- Wählen Sie die „Anzeige als XML“, „Anzeige mit Datenelementnamen“ oder „Anzeige mit Feldnamen“ je nach Präferenz.
- Wenn Sie Daten aufbereiten möchten, klicken Sie auf die einzelnen Prozesse 1-5, um Änderungen vorzunehmen.
- Wählen Sie rechts oben je nach Präferenz die „Editoransicht“ oder „Funktionsansicht“ aus – wir empfehlen die einfache „Funktionsansicht“ zu verwenden, in der zahlreiche „Funktionsbausteine“ zur Verfügung stehen (siehe Exkurs unten).
- Wählen Sie pro Prozessschritt die gewünschten Funktionsbausteine aus und nehmen Sie die passenden Einstellungen vor (ausführliche Dokumentation im PDF-Mapper-Handbuch).
- Alternativ können Sie in der „Editoransicht“ manuell die XSLT-Verarbeitung verändern. Dies ist nur Nutzern mit Kenntnissen in der Programmiersprache XSLT zu empfehlen.
- Klicken Sie auf „Speichern“, um den aktuellen Stand zu speichern.
- Überprüfen Sie die Änderungen unter „Neutralformat“ und wiederholen Sie ggf. Die Schritte 3-8.
- Klicken Sie auf „Änderungen aktivieren“, um die Änderungen für die automatische Verarbeitung zu aktivieren.
Testdaten: Im Normalfall setzen Sie bei der Umsetzung ein PDF-Dokument ein, das möglichst alle vorkommenden Fälle für die Anpassungen enthält. Da jedoch in der Praxis auch noch andere Fälle vorkommen, bei denen noch Anpassungen in den einzelnen Prozessschritten nötig sind, können Sie über den Button „Testdaten verwalten“ noch weitere PDF-Dokumente importieren. Der Button verfärbt sich grün, wenn ein Test-PDF ausgewählt ist.
Die 5 Prozessschritte: Es existieren fünf Prozessschritte, um mehrere Verarbeitungsschritte an einer Angabe durchführen zu können. Die Prozesse sind dabei für folgende Verarbeitungen gedacht: 1+2: Texte bereinigen und für weitere Funktionsbausteine vorbereiten 3: Daten harmonisieren (z. B. Datums- und Zahlenformate umwandeln) 4: Adressen erkennen, Daten nachbearbeiten 5: Variable Adressangaben erkennen
Exkurs: Funktionsbausteine
Die Funktionsbausteine beinhalten die am häufigsten verwendeten Anpassungsschritte zur Aufbereitung der ausgelesenen Daten. Hier geht es zu einer Liste der verfügbaren Funktionsbausteine.
Die Bausteine sind durch die Angabe von verschiedenen Parametern sehr flexibel einsetzbar. Wählen Sie einen Baustein, dann das gewünschte XML-Element und vervollständigen die jeweiligen Angaben je nach Funktion. Alle Funktionen sind mit nur einigen Klicks eingebaut und können ohne weitere XSLT-Kenntnisse verwendet werden.
Beispiel 6.1: Ein Datum automatisch formatieren
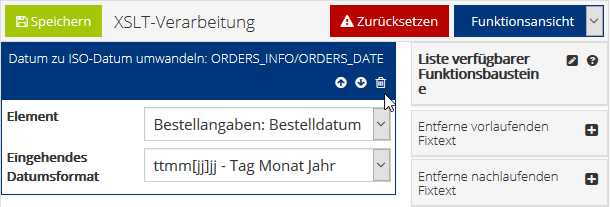
Wählen Sie den Funktionsbaustein „Datum zu ISO-Datum umwandeln“. Diese Funktion dient dazu, ein Datum aus einer Vielzahl von Formaten in das ISO-Datums-Format umzuwandeln.
Das erste Feld „Element“ bestimmt, auf welches XML-Element des ausgelesenen PDF-Dokuments die Funktion angewendet wird. Im Beispiel ist dies das Bestelldatum. Das zweite Feld „Eingehendes Datumsformat“ muss dem vorliegenden Format des Bestelldatums entsprechen.
Beispiel 6.2: Unnötige Texte entfernen
Wählen Sie den Funktionsbaustein „Entferne vorlaufenden Fixtext“, um Texte vor dem gewünschten Text zu entfernen, z.B. „Bestellnummer:“ im ausgelesenen Feld „Bestellnummer: 9067546“. Das erste Feld „Element“ bestimmt, auf welches XML-Element die Funktion angewendet wird. Im Dropdown-Menü „Vorlaufender Fixtext“ kann der zu bearbeitende Text ausgewählt werden (im Beispiel „Bestellnummer:“). Sobald er in das Feld darunter übernommen wurde, kann der zu behaltende Textausschnitt entfernt werden, sodass nur noch der zu entfernende Anfangstext zu sehen ist. Leerzeichen können entfernt/geglättet oder belassen werden.
Analog können Sie mit „Entferne nachlaufenden Fixtext“ Texte hinter dem gewünschten Text entfernen.

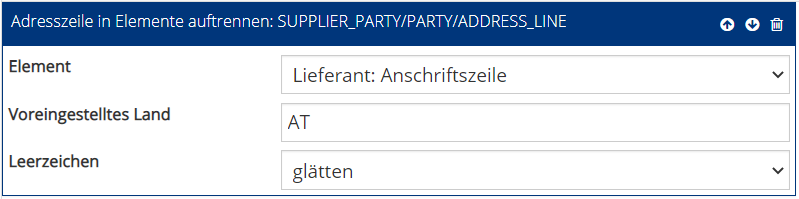
Beispiel 6.3: Adressen automatisch aufteilen
Dieser Schritt folgt z. B. auf den Sonderfall 5.4: Wählen Sie den Funktionsbaustein „Adresszeile in Elemente aufteilen“. Wählen Sie unter „Element“ das zu bearbeitende XML-Element. Der PDF-Mapper teilt nun die Adresse anhand des Zeichens „|“ in einzelne Felder auf. Unter „Voreingestelltes Land“ können Sie ein Land einstellen, das verwendet wird, falls auf dem PDF kein Land angegeben ist. Leerzeichen können entfernt/geglättet oder belassen werden.
7. ERP-Integration einstellen
Was machen wir hier?
Diesen Schritt muss nur global einmalig pro Schnittstelle zum ERP- oder Warenwirtschaftssystem durchgeführt werden. Er gilt dann für alle PDF-Mappings, die über diese Schnittstelle Daten übertragen sollen.
ERP-Systeme und andere Softwareanwendungen existieren wie Sand am Meer. Damit Sie die Daten aus den ausgelesen PDF-Dokumenten in jede Software einlesen können, können Sie im PDF-Mapper das Neutralformat zu einem beliebigen Inhouseformat umwandeln – also in das Format, das Sie für Ihre Schnittstelle benötigen.
Schritt für Schritt im PDF-Mapper
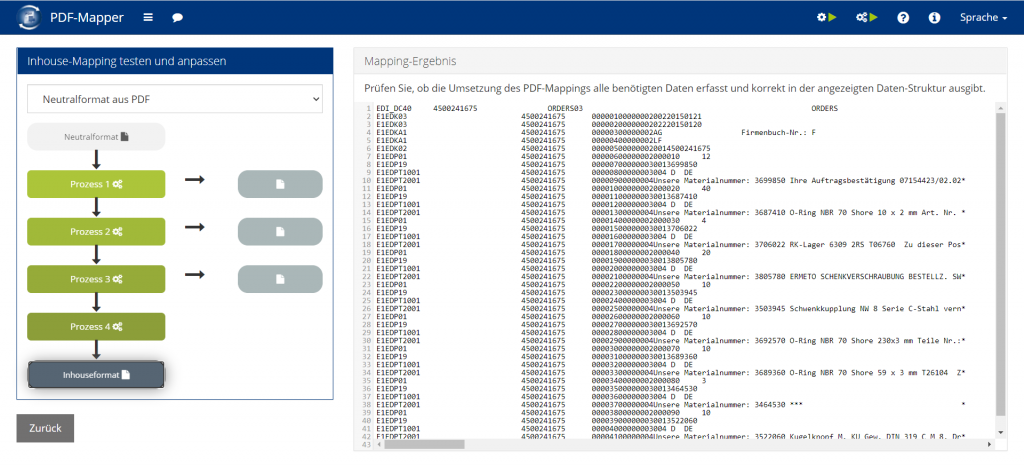
Inhouse-Mapping erstellen:
Für diesen Prozessschritt benötigen Sie IT-Kenntnisse über XSLT-Verarbeitungen. Falls diese Kenntnisse nicht in Ihrer Organisation vorhanden sind, können Sie die XSLT-Verarbeitung durch das PDF-Mapper-Team vornehmen lassen.
- Klicken Sie in der Mapping-Übersicht auf „Inhouse-Mapping bearbeiten“.
- Passen Sie den Code in den vier Prozessschritten wie gewünscht an.
- Klicken Sie auf „Speichern“, um den aktuellen Stand zu speichern.
- Überprüfen Sie Ihre Anpassungen, indem Sie auf „Inhouseformat“ klicken und so das Endergebnis anzeigen lassen.
- Wenn Sie zufrieden sind, klicken Sie auf „Änderungen aktivieren“, um die Änderungen an die automatische Verarbeitung zu übergeben.
Nicht-XML-Formate: Möchten Sie Nicht-XML-Formate wie CSV, SAP-IDoc oder Flatfile-Strukturen als Inhouseformat erzeugen, werden die Anpassungen von XML in das Nicht-XML-Format nur im vierten Prozessschritt vorgenommen. Verwenden Sie in diesem Fall in den Applikationseinstellungen normalerweise auch die Einstellung CSV-Format.
Testdaten: Zum Testen kann man aus dem oberen Drop-down Menü auch „Neutralformat aus Testdaten“ auswählen, damit Testdaten geladen werden, die alle möglichen Datenelemente beinhalten (und nicht nur die im Standard-PDF enthaltenen Datenfelder).
Daten ins ERP-System importieren
- Finden Sie den Importordner Ihres ERP- oder Warenwirtschaftssystems für die extrahierten Daten.
- Rufen Sie über die Navigationsleiste im PDF-Mapper die Applikationseinstellungen auf.
- Wählen Sie unter “Bestellverarbeitung” und “Rechnungsverarbeitung” das “Ausgabeverzeichnis für extrahierte Daten”.
- Wählen Sie den Importordner Ihres ERP- oder Warenwirtschaftssystems als Ausgabeverzeichnis aus.
- Klicken Sie auf “Speichern”.
Sonderfall 7.1: Ich habe mehrere Schnittstellen für meine verschiedenen PDF-Dokumente
Die Inhouse-Mappings für Bestellung und Rechnung werden getrennt erstellt. Wenn Sie aber z.B. Bestellungen und Auftragsbestätigungen (unter der gemeinsamen Konfiguration Bestellungen) zu unterschiedlichen Ausgabeformaten verarbeiten möchten, können Sie die Gültigkeit einzelner XSLT-Mappingregeln bspw. über die mode-Angaben unterscheiden, also <xsl:template match=“{feldname}“ mode=“order“>… und <xsl:template match=“{feldname}“ mode=“orderresponse“>…
8. Validierung einstellen
Was machen wir hier?
Diesen Schritt müssen Sie nur global einmalig pro Dokumenttyp einstellen. Die Validierung gilt dann für alle PDF-Mappings dieses Dokumenttyps.
Damit Daten aus PDF-Dokumenten nicht an das ERP-System übergeben werden, obwohl wichtige Daten fehlen oder fehlerhaft sind, gibt es die automatische Validierung. Dort können Validierungsregeln eingestellt werden, die erfüllt werden müssen. Wenn ein PDF-Dokument die Validierungsregeln nicht erfüllt, können die Daten im PDF-Mapper manuell angepasst werden oder in ein spezielles Verzeichnis für fehlerhafte Belege ausgegeben werden.
Schritt für Schritt im PDF-Mapper
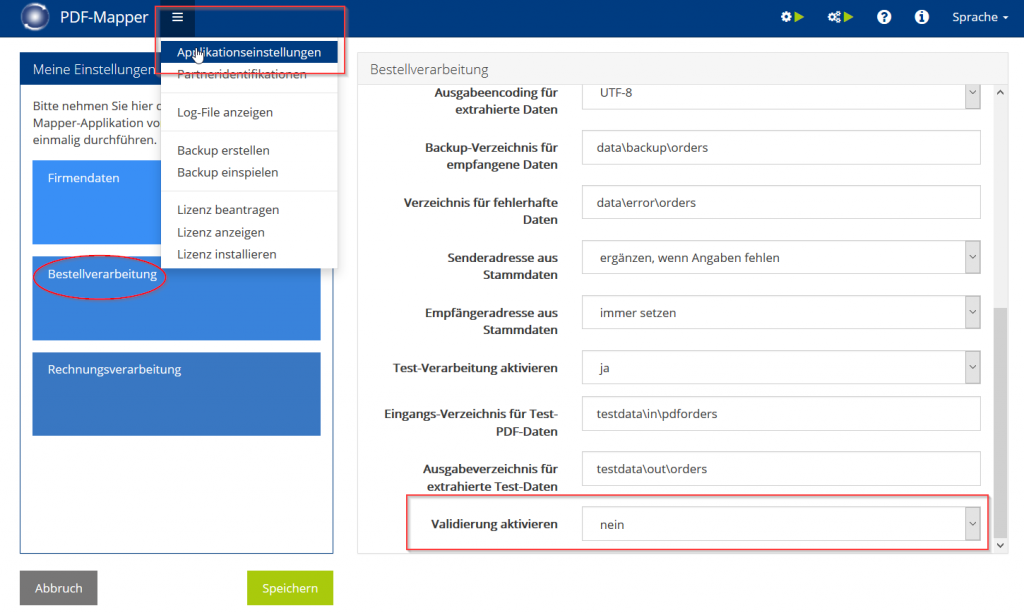
Validierung aktivieren:
- Aktivieren Sie die Validierung in den Applikationseinstellungen unter „Bestellverarbeitung“ und/oder „Rechnungsverarbeitung“.
- Legen Sie dann in der „Bestellvalidierung“ oder „Rechnungsvalidierung“ fest, ob fehlerhafte PDFs in ein Fehlerverzeichnis ausgegeben oder im PDF-Mapper korrigiert werden sollen.
- Ändern Sie ggf. den Ordnerpfad für das Fehlerverzeichnis oder die Belegkorrektur.
- Aktivieren Sie ggf. die Option, dass Sie per Nachricht informiert werden, wenn PDFs fehlerhaft sind.
Validierung einstellen:
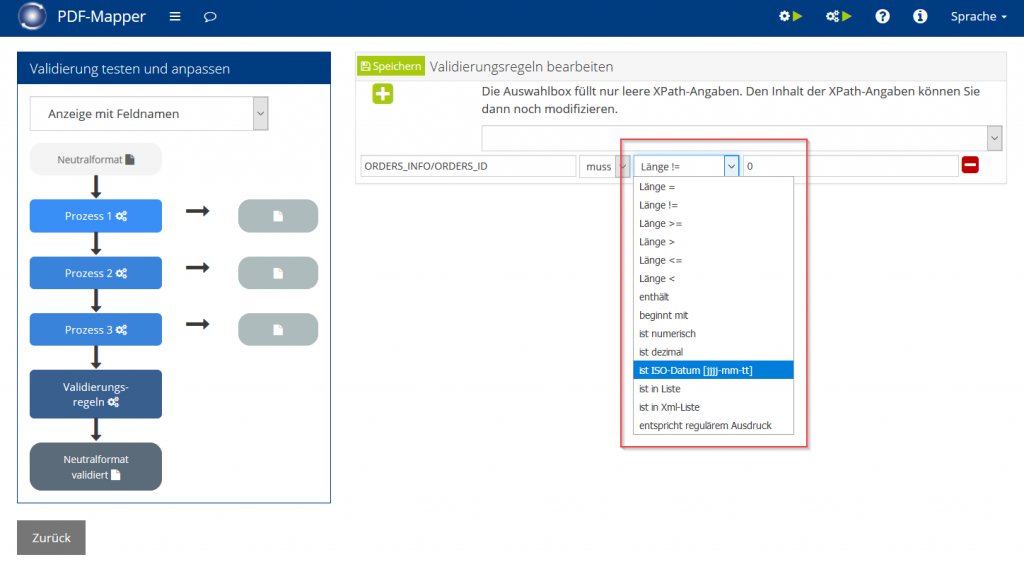
- Um die Validierungsregeln einzustellen, gehen Sie unter „Mapping bearbeiten“ auf „Validierung“, klicken Sie auf „Validierung anpassen“ und dann auf „Validierungsregeln“.
- Wählen Sie aus dem Dropdown-Menü ein XML-Element aus, zu dem Sie eine Regel erstellen möchten.
- Legen Sie fest, ob das ausgewählte Element auf einem PDF-Dokument vorhanden sein muss oder kann.
- Wählen Sie eine Funktion aus der Dropdown-Liste aus und nehmen Sie ggf. die passenden Angaben vor.
- Klicken Sie auf „Speichern“, um den aktuellen Stand zu speichern.
- Überprüfen Sie die Validierungsregeln über „Neutralformat validiert“.
- Klicken Sie auf „Änderungen aktivieren“, um die Validierung für die automatische Verarbeitung zu aktivieren.
Anzeige erweitern: Wenn Sie die Einstellung "Anzeige erweitert" wählen, können Sie zu jeder Regel noch einen Beschreibungstext ergänzen, der auch in der Ansicht für die Belegkorrektur zusätzlich angezeigt wird.
Die 3 Prozessschritte: Die Prozessschritte 1-3, die den Validierungsregeln vorgeschaltet sind, können Sie dafür verwenden, um z. B. komplexe Auswertungen per XSLT in ein Datenfeld zu schreiben, das Sie anschließend in den Validierungsregeln auswerten können. Normalerweise werden Sie hier keine Konfiguration vornehmen müssen.
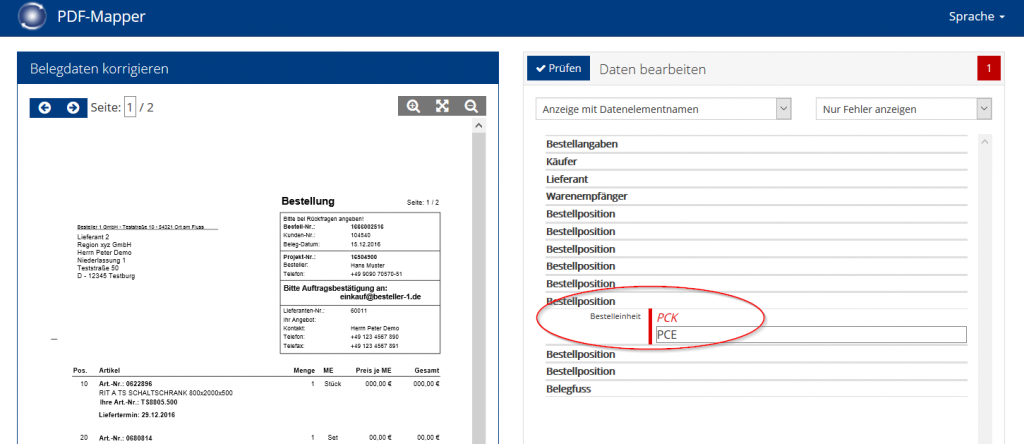
Fehlerhaftes PDF korrigieren:
- Um einen fehlerhaften PDF-Beleg zu korrigieren, können Sie in der obersten Navigationsleiste auf die „Belegübersicht für Korrektur“ klicken.
- Wählen Sie den fehlerhaften Beleg aus der Übersicht und klicken Sie auf „Beleg korrigieren“.
- Korrigieren Sie die rot markierten fehlerhaften Felder.
- Klicken Sie auf „Prüfen“, um zu testen, ob Ihre Änderungen den Validierungsregeln entsprechen.
- Klicken Sie dann auf „Verarbeiten“, um den Beleg an Ihr ERP-System zu übergeben.
Sonderfall 8.1: Per E-Mail über fehlerhafte Belege benachrichtigt werden
In den Applikationseinstellungen können Sie festlegen, ob an einen oder mehrere Email-Accounts Nachrichten geschickt werden sollen, sobald ein fehlerhafter Beleg auftaucht. Die Nachrichten können je nach Partner auf verschiedene Email-Adressen aufgeteilt werden.
Eingehende PDF-Dokumente automatisch im Hintergrund auslesen
Was ist unser Ergebnis?
Nachdem wir ein oder mehrere PDF-Mappings durchgeführt haben und die Applikationseinstellungen sowie die ERP-Integration eingestellt haben, können PDF-Dokumente vollautomatisch ausgelesen, verarbeitet, in EDI-/XML-Dateien konvertiert und in Ihr Warenwirtschaftssystem eingelesen werden. Die automatische Konvertierung von PDF zu Ihrem Wunschformat findet ganz im Hintergrund statt, während Sie sich anderen Aufgaben widmen können!
Eingehende PDF-Dokumente können manuell in einen Import-Ordner geschoben werden oder automatisch aus einem Email-Postfach abgeholt werden.
Was passiert im PDF-Mapper?
- Ein PDF-Dokument kommt im Import-Ordner oder im ausgewählten Email-Postfach an.
- Das PDF wird in ein Backup-Verzeichnis für empfangene Daten abgelegt.
- Es wird überprüft, ob das PDF einem hinterlegtem Partner zugeordnet werden kann – falls nicht, wird es in einem Fehler-Verzeichnis abgelegt, ansonsten wird es verarbeitet.
- Das PDF wird ausgelesen, verarbeitet, in das gewünschte EDI-/XML-Format konvertiert und in einen Ausgabe-Ordner ausgegeben – von dort kann es automatisch in die gewünschte Schnittstelle des Warenwirtschaftsystems eingelesen werden.
- Falls die Validierung aktiviert wurde und Daten im PDF fehlen oder fehlerhaft sind, können die Daten manuell angepasst werden.
Anmerkung: Damit die automatische Konvertierung korrekt durchgeführt wird, muss das passende PDF-Mapping richtig eingestellt sein.
Wie kann ich starten?
Wenn Sie bis hierhin gelesen und den PDF-Mapper noch nicht installiert haben, ist es jetzt höchste Zeit! Starten Sie Ihren kostenlosen Test oder kontaktieren Sie unser freundliches Vertriebsteam.
